Abstract
About the Author
This project was completed by Robert Luo, an Applied Mathematics student at Northwestern University (graduating Spring 2018). Please feel free to send comments or feedback to robertluo@u.northwestern.edu. An in-depth report of this project can be downloaded here.
About the Project
Yelp is an online platform where users can submit reviews about restaurants and businesses. A business’ Yelp rating and its written reviews can attract or repel visitors, and consequently determine the success of the business. Many consumers depend on Yelp as well. In today’s day and age, access to crowd-sourced reviews can highly influence consumer decisions on what stores to shop at and restaurants to dine in. A model that can predict when a Yelp reviewer will rate a restaurant highly (4 or 5 stars) can serve as a valuable recommender system, potentially increasing user engagement and retention as well as customer traffic to new restaurants.
This project evaluates the performance of User-Item Collaborative Filtering, Item-Item Collaborative Filtering, and K-Nearest Neighbor Collaborative Filtering in predicting Yelp user ratings of restaurants in the United States.
To define these methods:
- User-Item CF: “Users similar to you liked…”
- Item-Item CF: “Users who liked this restaurant also liked…”
- K-NN CF: “You might like this item based on your ratings of K similar items…”
I downloaded my dataset from the Yelp dataset challenge, and used data consisting of user reviews and business features. I created a matrix of user-restaurant-ratings to for all three methods. I also created a one-hot matrix of restaurants and their attributes to use for K-NN CF. Due to the size of the Yelp dataset, I chose to only consider users and restaurants in the US with at least 15 reviews in order to avoid the cold-start problem related to recommender systems (this remains unaddressed throughout the project). Some of the features considered in the one-hot matrix used for K-NN CF include: cuisine type, restaurant attire, ambience, alcohol availability, and price range. Categorical variables were converted to one-hot attributes, for a total of 170 attributes. In total, my processed dataset considered 5186 restaurants and 10634 users. There were 248838 ratings used for training, 31170 used for validation, and 10390 held out for testing (roughly an 85/10/5 split). I used scikit-learn to assist with the project, along with some implementation of my own. Code and processed data can be found in the repository.
Results
User-Item CF root-mean-squared error and mean-absolute-error are:
| Evaluation Measure | User-Item | Item-Item |
|---|---|---|
| RMSE | 3.907 | 3.921 |
| MAE | 3.731 | 3.746 |
Although these results are not stellar, it is promising that we can predict user ratings off of similarity measures.
The figure below shows the K-NN performance evaluated against the validation set with a range of K values, where metrics are calculated from classifications of: rating above 4 = “High”, rating below 4 = “Low”.
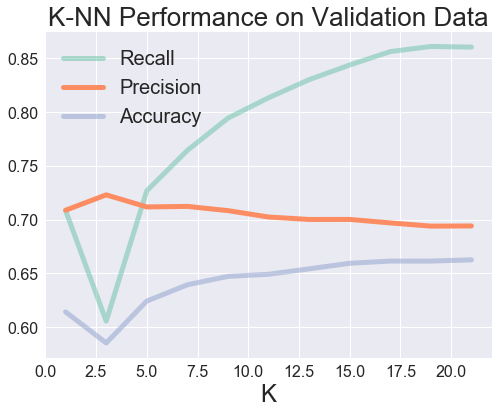
Although the accuracy of prediction is not stellar, we must also consider precision and recall. Precision is the ability of the classifier to not incorrectly label an observation positive that is actually negative. It is important to have a high precision score in order to not recommend a would-be-low-rated-restaurant to a user. Recall is the ability of the classifier to find all the positive samples. A recommender with a high recall score is able to recommend users most of the restaurants he or she would rate highly.
It can be observed that the K-NN CF model achieves high recall at K = 20. At this point, accuracy has plateaud and precision has begun to decrease. With a preference for high recall score, I chose K = 20 as the optimal K.
The results after running 20-NN CF on the test set, the answers are:
| Evaluation Measure | 20-NN CF |
|---|---|
| Recall | 0.870 |
| Precision | 0.688 |
| Accuracy | 0.663 |
The model performs very similar as it did on the validation set! In conclusion, although 20-NN CF does not produce high accuracy, it does achieve high recall. This suggests that a recommender created with 20-NN CF would be able to recommend users most of their to-be-highly-rated restaurants.
Acknowledgements
The following guides were very helpful for the implementation of my project: